metadata-service
Configuring the Gen3 Aggregate Metadata Service and Adapters
An adapter handles ingesting data into the Aggregate Metadata Service. An adapter is used to interface with a metadata API to pull study or item metadata into the Aggregate Metadata Service. The adapter is called when the Aggregate MDS is populated, either when it is started or on-demand. The adapter helps in the ETL process to pull, cleanup, and normalize metadata before it is loaded. The adapters are configurable by a JSON object which is described below.
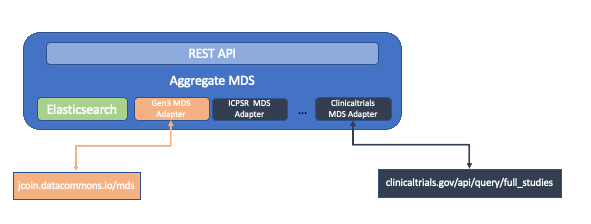
Adapters enable pulling metadata from a remote service
Introduction
The adapter works in the following order of operations:
- Initialize the adapter with the parameters read from the configuration file.
- Access the remote data API via an HTTP GET or POST command
- Depending on the API and parameters, pull all data or a selected subset of Metadata
- For each pulled metadata entry:
- normalize metadata field (i.e. map remote name to standard name)
- optionally filter the field data (remove HTML tags, email addresses, etc.)
- optionally add original fields into a normalized entry
- apply global filters
- Add per item values
Configuration
A metadata service is configurable via a JSON object, with the following format: ```json lines “configuration”: { “schema”: { … }, “settings”: { … } }, “adapter_commons”: { Adapters Configuration }
### Schema
The schema section is optional. It allows the user to have a finer level of control over the Elasticsearch backend and if defined,
will allow for schema introspection via a JSON schema.
A schema is of the form:
```json lines
"schema": {
"__manifest": {
"description": "an array of filename (usually DRS ids and its size",
"type": "array",
"properties": {
"file_name": {
"type": "string"
},
"file_size": {
"type": "integer"
}
}
},
"commons_url": {},
"short_name": {
"default" : "not_set"
},
"tags": {
"type": "array"
},
Where each defined field can be defined with the data type, description, and a default value. All are optional, the default type is string. Note any field defined in an adapter field mapping section below NOT defined in the
schema will be added and auto-typed by Elastic search. The purpose of the schema is to provide a way to explicitly type fields, especially nested object (for example __manifest above).
It also allows for a default value to be defined an aggregate metadata field will be set to if the value is not present in a metadata object.
This also allows for introspection by returning a JSON schema form using the info API call:
http://localhost:8000/aggregate/info/schema
{
"_subjects_count": {
"type": "integer",
"description": ""
},
"__manifest": {
"type": "array",
"properties": {
"file_name": {
"type": "string",
"description": ""
},
"file_size": {
"type": "integer",
"description": ""
}
},
"description": "and array of filename (usually DRS ids and its size"
},
"tags": {
"type": "array",
"description": ""
},
"_unique_id": {
"type": "string",
"description": ""
},
"study_description": {
"type": "string",
"description": ""
},
"study_id": {
"type": "string",
"description": ""
},
"study_url": {
"type": "string",
"description": ""
},
"project_id": {
"type": "string",
"description": ""
},
"short_name": {
"type": "string",
"description": "",
"default": "not_set"
},
"year": {
"type": "string",
"description": "",
"default": "not_set"
},
"full_name": {
"type": "string",
"description": ""
},
"commons_url": {
"type": "string",
"description": ""
},
"commons": {
"type": "string",
"description": ""
}
}
Settings
DRS Caching
- cache_drs : [true|false] - if set to true, the adapter will
connect to dataguids.org and cache the DRS directory information. This information is available via the
into API endpoint:
http://localhost:8000/aggregate/info/dg.H35L{ "host": "externaldata.healdata.org", "name": "External Data HEAL", "type": "indexd" }
Array config prefix
- array_config_prefix : [string] - if set, the prefix to add to all arrays defined in the schema. This is useful for when using the aggregate metadata elastic search with the Explorer page of the Gen3 front end.
Adapter Configuration
The adapter_commons section of the configuration file is used to define where the aggregate metadata service will pull data from.
There can be any of adapters, in fact a single Gen3 commons can be queried more than once by defining different adapter settings.
{
...
"ICPSR": {
"mds_url": "https://www.icpsr.umich.edu/icpsrweb/neutral/oai/studies",
"commons_url": "https://www.icpsr.umich.edu",
"adapter": "icpsr",
"filters": {
"study_ids": [30122, 37887, 37833, 37842, 37841, 35197 ]
},
"field_mappings" : {
"tags": [],
"sites": "",
"year" : "2020",
"shortName":"study_name",
"location": "path:coverage[0]",
"summary": {
"path":"description",
"filters": ["strip_html"],
"default_value" : "N/A"
},
...
},
"per_item_values" : {
"10.3886/ICPSR30122.v5": {
"__manifest": [
{
"md5sum": "7cf87ce47b91e3a663322222bc22d098",
"file_name": "example1.zip",
"file_size": 23334,
"object_id": "dg.XXXX/208f4c52-771e-409a-c920-4bcba3c03c51",
"commons_url": "externaldata.commons1.org"
}
],
"data_availability": "available",
"authz": "/programs/open",
},
...
}
}
...
}
A sample configuration file
For a fully working configuration file to pull sample data from gen3.datacommons.io is here.
Any number of adapters can be added to a configuration file as long as the commons name (used as a key) per adapter is unique.
Parameters
The parameters of an adapter are:
mds_url: URL of the metadata serviceAPI.commons_url: the URL for the homepage the metadata sourcecommons_name: override the commons_name. Typically, the commons are named using the entry name for the adapter. (ICPSR in the above config file). However there are case where using a different name is preferred. For example, if one of more adapters are assigned the same name, all the entries will be added to the commons name in the aggregateMDS. This can use to have multiple adapters pull data from the same source but using different mappings of filtering operations.adapter: registered name of the adapter, used to bind a particular adapter to a site: NOTE there is no checking to ensure that the correct adapters are being used. Usually, in the case of a mismatch, errors are logged and nothing is pulled.config: an object defining any additional parameters needed for an adapter (see Gen3 Adapter below).filters: the parameters (or filter properties) passed to the adapter, this is adapter-specific. In the above example, thestudy_idparameter for the ICPSR adapter is used to select which study ids to pull from ICPSR. Note that adapters themselves can have filtering options, this is provided as a backup if no other filter option is available.
Adapter Setting
- keep_original_fields
[true|false]- allows the adapter to add all of the original field in a study when loading. If set to true, any field already defined and process will be updated to the processed value.
Sometimes a need arises to filter entries based on a field value. select_fields
config provides a way to filter out data that does NOT match. The setting are:
- field_name - the field name to filter. Note that the filter is executed after the data has been processed, so the values need to be mapped or normalized name
- field_value - set to a string. Any fields NOT matching this value will not be added.
A sample:
...
"select_field": {
"field_name": "data_resource",
"field_value": "SAMHDA"
},
...
Field Mappings
The next section of the configuration, field mappings, map field names from the remote metadata into a standard name. This process is also called normalization. The mapping is simply the name of the normalized field (what is stored in the Aggregate metadata service ) to the remote field. Think of it as AggMDS field = Remote Field. While this works for simple cases, there are many instances where the field is deeper in a JSON object. To resolve this, you can specify a path selector
Selectors
A path from the start (or root) of a remote metadata field can be described using JSON path syntax. JSON path can be used by prefixing path: to a JSON path expression to the field you want to get the value for. For example, if you wanted to get the first official name in the array OverallOfficial the selection would be path:OverallOfficial[0].OverallOfficialName
You can experiment with JSON paths using a JSON Path editor.
Filters
The above methods should allow you to pull any nested value from a metadata entry. There are also cases where the metadata needs further processing or filtering. While this can be done in Python, by writing a new or extending an existing adapter, there is also the option to apply a filter. A filter can be added to a field using the long mapping form:
"summary": {
"path":"description",
"filters": ["strip_html"],
"default" : "N/A"
}
In this case, the summary is set to a JSON object which optionally defines:
- a JSON path
- an array of one or more filters to apply
- default value to set if that field is not found
The filters are applied to the text value of the remote field. Furthermore, the filters are applied in the order they appear. The current set of filters are:
- strip_html: remove HTML tags from a text field
- strip_email: remove email addresses from a text field
- add_icpsr_source_url: creates an url to the study data on ICPSR
- add_clinical_trials_source_url: creates an url to the study on clinicaltrials.gov
- normalize_value: normalized a value by mapping from one value to another. This uses a mapping object passed as a filter parameter.
For example:
"subject_cancerStage: { "path": "cancerStage", "filters": [ "normalize_value" ], "filterParams": { "normalize_value": { "2": "Stage 2", "3": "Stage 3" } }, "default": "" },Will map values of ‘2” to ‘Stage 2’ and ‘3’ to ‘Stage 3. This can be used to normalize data values from different data sources.
- normalize_tags: normalizes tag values by defining a mapping of category names to new name values.
Example:
"tags": { "path": "tags", "filters": [ "normalize_tags" ], "filterParams": { "normalize_tags": { "CancerStage": { "Stage II": "Stage 2", "Stage III": "Stage 3" } } } },Will normalize the tage category ‘CancerStage’ to Stage 2 and Stage 3.
- strip_leading_double_underscore will remove __ from data field keys for all objects and sub-objects.
Example:
"filesCount": { "path": "filesCount", "filters": [ "strip_leading_double_underscore" ] },Will remove all
__(double underscores) from any child object in the field ``filesCount`. For example:"filesCount": [ { "data_category": "Peptide Spectral Matches", "file_type": "Open Standard", "files_count": 419, "__typename": "File" },is converted to:
"filesCount": [ { "data_category": "Peptide Spectral Matches", "file_type": "Open Standard", "files_count": 419, "_typename": "File" },
You can add your own filters and register them by creating a python function with the signature:
def filter_function(s:str) -> str:
...
Default Values
Defining default values for fields is handled in one of two ways:
If a field in the metadata does not need a path, simply define the
field name and a value. If a remote metadata field has a value, it will override the default.
If a path is used, then use the longer form and set the default to use
if the path is not found. The longer form of a field mapping is:
```json lines
“summary”: {
“path”:”description”,
“filters”: [“strip_html”],
“default” : “N/A”
},
where:
* ```path``` is the json path to the field
* ```filters```: list of filters to apply (optional)
* ```default```: value to set the field to if the path does not resolve (also optional)
```json
{
...
"summary": {
"path": "description",
"filters": [
"strip_html"
],
"default": "N/A"
},
...
}
Nested Field Names
(New in 3.1.0) The field mapping now supports setting up nested fields in a result by using JSON path syntax as field names. For example, the following field mapping
"study_metadata.summary": {
"path":"description",
"default" : "N/A"
}
will yield to a result like this as output
"study_metadata":{
"summary": "This is a summary"
}
Per Item Overrides
The configuration file also supports what is called per item overrides. This allows you to override or add values to specific metadata entries after they are normalized but before they are added to the Aggregate Metadata. To override an item value, add a JSON object with the id of the item you want to override, as shown in the figure above. The JSON object should set each field that you to override. In the case the item is not present, the per item values are ignored. If the per item values are not present in the normalized fields, they are added.
Writing a new Adapter
Creating a new adapter requires writing a class in Python. The minimal effort would require writing a REST call to the remote adapter and is adding to the adapter registry. The Adapter SDK provides a base class which can be extended as needed. The base class is shown below:
class RemoteMetadataAdapter(ABC):
@abstractmethod
def getRemoteDataAsJson(self, **kwargs) -> Tuple[Dict, str]:
""" needs to be implemented in derived class """
@abstractmethod
def normalizeToGen3MDSFields(self, data, **kwargs) -> Dict:
""" needs to be implemented in derived class """
@staticmethod
def mapFields(item: dict, mappings: dict, global_filters: list = []) -> dict:
"""
maps fields from the remote field name to the normalized, or
standardized version. Unless you need special processing this function can be used as-is.
parameters:
* item: metadata entry to be mapped
* mappings: a dictionary of the remote field to normalize, this
passed in from the configuration file_name
* global_filters to apply
"""
@staticmethod
def setPerItemValues(item: dict, perItemValues: dict) -> None:
"""
Overrides the item field values with those in perItemsValues.
parameters:
* item: metadata entry to override
* perItemValues: a dictionary of field names to values
"""
The two functions you need to override are: getRemoteDataAsJson and
normalizeToGen3MDSFields. The first will call a remote API and return a dictionary of the form:
results = {"results": []}
where each entry in the array is a JSON/Python dict. This function typically requires the least custom code. Feel free to use the existing set of adapters as a guide. The code can be found in adapters.py
The second function normalizeToGen3MDSFields is usually quite
simple to code, and usually requires an additional function which is named addGen3ExpectedFields. The code below is very typical for an adapter.
def addGen3ExpectedFields(item, mappings, keepOriginalFields, globalFieldFilters):
"""
Given an item (metadata as a dict), map the item's keys into
the fields defined in mappings. If the original fields should
be preserved set keepOriginalFields to setPerItemValues.
* item: metadata to map fields from -> to
* mapping: dict to map field_name (possible a JSON Path) to a normalize_name
* keepOriginalFields: if True keep all data in the item, if False only those fields in mappings
will be in the returned item
* globalFieldFilters: filters to apply to all fields
"""
results = item
if mappings is not None:
mapped_fields = RemoteMetadataAdapter.mapFields(
item, mappings, globalFieldFilters
)
if keepOriginalFields:
results.update(mapped_fields)
else:
results = mapped_fields
return results
The above code basically checks to see if any mapping is defined. If not
then the item is returned. If a mapping does exist then we call RemoteMetadataAdapter.mapFields which will do the mapping and apply
any filters. If you want to keep the original fields, set keepOriginalFields to true. This function usually can be used as is, however, in some cases if there is
a need for additional per-item processing, it should be done in this function.
def normalizeToGen3MDSFields(self, data, **kwargs) -> Dict[str, Any]:
"""
Iterates over the response.
* data: input metadata to normalize
* kwargs: key value parameters passed as a dict
return: dict of results where the keys are identifiers in the Gen3 metadata format:
"GUID" : {
"_guid_type": "discovery_metadata",
"gen3_discovery": normalize_item_metadata
}
"""
mappings = kwargs.get("mappings", None)
study_field = kwargs.get("study_field", "gen3_discovery")
keepOriginalFields = kwargs.get("keepOriginalFields", True)
globalFieldFilters = kwargs.get("globalFieldFilters", [])
# process any configuration parameters
config = kwargs.get("config", {})
study_field = config.get("study_field", "gen3_discovery")
results = {}
for guid, record in data["results"].items():
item = Gen3Adapter.addGen3ExpectedFields(
record[study_field], mappings, keepOriginalFields, globalFieldFilters
)
results[guid] = {
"_guid_type": guid_type,
"gen3_discovery": item,
}
perItemValues = kwargs.get("perItemValues", None)
if perItemValues is not None:
RemoteMetadataAdapter.setPerItemValues(results, perItemValues)
return results
The code above does the following:
- Extract the parameters from the kwargs (dict of parameters)
- optionally process any configuration values
- For each (id, item) received from the remote metadata API:
* map study fields to normalize name by calling
addGen3ExpectedFields* Set the results into a dictionary of metadata GUIDS - Apply any perItemValues defined in the config file
- Return the results
While the Adapters support Object-Oriented Programming, you actually do not need to extend from the classes as long as you create a class with the above signature you should be fine.
Adding your Adapter
Adding your adapter and or filters to be called by the populate process is still in the design phase. Currently, this requires adding the adapter code into the source code of the Gen3 metadata-service. However, shortly we will move to a plugin-based model.
Gen3 Adapter
The Gen3 Adapter is used to interface and retrieve data from a Gen3 Datacommons running a metadata-service. The configuration for the Gen3 Commons is identical to what is described above. The config section provides a way define what _guid_type and field to read an entry from.
Configuring the metadata schema
Note that the Gen3 metadata is typically in this format:
```json lines “ds000030”: { “_guid_type”: “discovery_metadata”, “gen3_discovery”: { …
The ```_guid_type``` and ```gen3_discovery``` usually default to
```"discovery_metadata"``` and ```"gen3_discovery"```. However, this is not always the case.
To account for these differences you can add the following to a Gen3 adapter config section
where ```guid_type``` sets the string for ```_guid_type```
```study_field``` set the name of the metadata filed within
the ```guid_type``` object.
```json lines
"config" : {
"guid_type": "unregistered_discovery_metadata",
"study_field": "my_metadata"
},
this will the look for metadata entries such as:
```json lines “ds000030”: { “unregistered_discovery_metadata”: “discovery_metadata”, “my_metadata”: { …
### Advanced filtering
The Gen3 metadata-service supports filtering as described in the documentation. The Gen3 Adapter
supports a filtering option which is passed to the MDS. This way, specific studies that match only the
filters will be pulled from the MDS.
The filters are part of the config setting:
```json lines
"config": {
"filters": "gen3_discovery.data_resource=SAMHDA"
},
Note that this can work along with the guid_type and study_field.