High-Resolution, Spinal Cord Stimulation for Non-Opioid Treatment of Neuropathic Pain
- Prepared by:
- J M Maxwell, Center for Translational Data Science (CTDS), University of Chicago
Attribution
This notebook uses data collected by Quintero et al. (2024) as part of their study entitled Correlating Evoked Electromyography and Anatomic Factors During Spinal Cord Stimulation Implantation With Short-Term Outcomes. The data have been archived by the authors at Mendeley Data and are accessible via the HEAL Data Platform.
The purpose of this notebook is to demonstrate how the data may be accessed and used for analysis, and is intended to be used as a jumping off point for researchers who may wish to use these data for their own secondary analyses. While some of the analyses below may recreate analyses presented in the original publication, they are not intended to replicate the original results and differences in analytic methods and software, selection/filtering of observations, and handling of missing data may yield results that differ from the original.
The work here was conducted without direct involvement of the original authors and therefore does not necessarily reflect the views or opinions of the authors, of the NIH HEAL Initiative®, or of the Center for Translational Data Science (CTDS) at the University of Chicago.
About the Study¶
The study, High-Resolution, Spinal Cord Stimulation for Non-Opioid Treatment of Neuropathic Pain, investigated the outcomes of elliciting EMGs (electromyography) in subject’s regions of pain during surgery. Data for evaluating the treatment effect were collected from 21 patients in two phases. Subject outcomes were measured using: the Numerical Rating Scale, McGill Pain Questionnaire, Beck Depression Inventory, Oswestry Disability Index, and Pain Catastrophizing Score, and were recorded preoperatively and at three months following the procedure.
Setup¶
This notebook uses Python (tested with version 3.13) and relies on several modules and third-party packages. Thus we start by installing and/or importing these if necessary (click on the bar below to expand the cell and see the code).
Notebook Cell
!pip install pandas openpyxl gen3 tableone scipy matplotlib -q
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
from IPython.display import Markdown, Image, displayRetrieving the Data¶
The data used here are archived at Mendeley Data. Accessing these data through the Platform currently requires that you login using one of the options provided. After doing so, you may download the data directly from the Study Page (under the Data tab) or you may download them using the gen3 command, as we will do here.
Each file indexed by the Platform is assigned a globally unique identifier (GUID) that may be used to retrieve the file. Here we download two files using their GUIDs.
if not os.path.exists('Microleads - Participant level data.xlsx'):
!gen3 drs-pull object dg.H34L/b8b871b8-aadd-4017-9f67-184b17ab3580
if not os.path.exists('Pain-MRI scores.xlsx'):
!gen3 drs-pull object dg.H34L/ffde8647-1ec2-4459-8409-bd41c0736c86Reading and Cleaning the Data¶
After reading in the data, we perform standard data cleaning steps to improve the usability of the data, remove extraneous data features, and engineer new features measuring the percent change in treatment effects from before and after the each sample subject’s operation.
participants_df = pd.read_excel('Microleads - Participant level data.xlsx')
pain_scores_df = pd.read_excel('Pain-MRI scores.xlsx')
pain_scores_df = pain_scores_df.iloc[:21, :]
df = pd.merge(left=participants_df, right=pain_scores_df, how='left', on=['Phase', 'Patient'])
df[list(df.select_dtypes(include='float64'))] = df[list(df.select_dtypes(include='float64'))].astype('float32')
df.replace('-', np.nan, inplace=True)
df.rename(columns={'NRS Pre-op': 'NRS Pre-Op', 'NRS Post-op': 'NRS Post-Op', 'MPQ pre-op': 'MPQ Pre-Op', 'MPQ post-op': 'MPQ Post-Op', 'Gender': 'Sex'}, inplace=True)
df.drop(['Patient', 'Race', 'Ethnicity', 'Age Unit'], axis=1, inplace=True)
delta_cols = ['NRS', 'MPQ', 'ODI', 'PCS', 'BDI']
for col in delta_cols:
df[f'{col}_pct_change'] = np.round(100*((df[f'{col} Post-Op'].astype('float') - df[f'{col} Pre-Op'].astype('float'))/df[f'{col} Post-Op'].astype('float')), 2)
df.replace(np.float64('-inf'), np.nan, inplace=True)Summary Statistics¶
First, let us look at the summary statistics for our measured treatment effects and our engineer treatment effects.
characteristics = ['Sex M/F', 'Age', 'Anterior-posterior diameter (mean ± SD in mm)',
'Interpedicular distance (mean ± SD in mm)', 'Dorsal CSF thickness (mean ± SD in mm)',
'Numerical Rating Scale (mean ± SD)', 'McGill Pain Questionnaire (mean ± SD)',
'Oswestry Disability Index (mean ± SD)', 'Pain Catastrophizing Scale (mean ± SD)', 'Beck Depression Index (mean ± SD']
cols = ['Age', 'AP column Diameter (mm)', 'Interpedicular distance (mm)', 'Dorsal CSF Thickness (mm)',
'NRS Pre-Op', 'MPQ Pre-Op', 'ODI Pre-Op', 'PCS Pre-Op', 'BDI Pre-Op', ]
x = df.Sex.value_counts().values
values = [f'{int(x[1])} / {int(x[0])}']
for col in cols:
values.append(f'{np.round(float(df[col].mean()), decimals=1)} ' + u"\u00B1" + f' {np.round(float(df[col].std()), 1)}')
pd.DataFrame({'Patient Information and Clinical Characteristics': characteristics, 'Values': values}).style.hide(axis='index')characteristics = ['Numerical Rating Scale Percent Change (mean ± SD)', 'McGill Pain Questionnaire Percent Change (mean ± SD)',
'Oswestry Disability Index Percent Change (mean ± SD)', 'Pain Catastrophizing Scale Percent Change (mean ± SD)',
'Beck Depression Index Percent Change (mean ± SD']
cols = ['NRS_pct_change', 'MPQ_pct_change', 'ODI_pct_change', 'PCS_pct_change', 'BDI_pct_change']
values = []
for col in cols:
values.append(f'{np.round(float(df[col].mean()), decimals=1)} ' + u"\u00B1" + f' {np.round(float(df[col].std()), 1)}')
pd.DataFrame({'Patient Information and Clinical Characteristics': characteristics, 'Values': values}).style.hide(axis='index')Statistical Testing¶
We’re interested in comparing the treatment effects pre and post subject’s operations. To begin with, we can use the Shapiro-Wilk Test to determine if the differences between each set of distributions are potentially normally distributed.
The null hypothesis is that the difference between the distributions of each treatment effect pre and post operation are not normally distributed. If we reject the null hypothesis, then we will proceed assuming the difference in distributions is not normally distributed. If we fail to reject the null hypothesis, then we will assume the distributions could be normally distributed.
fig, axes = plt.subplots(2, 3, figsize=(12, 6)) # Adjust the figure size as needed
axes = axes.flatten()
delta_cols = ['NRS', 'MPQ', 'ODI', 'PCS', 'BDI']
for i in range(0, len(delta_cols)):
data = (df[f'{delta_cols[i]} Post-Op'] - df[f'{delta_cols[i]} Pre-Op']).dropna().astype('float')
stat, p = stats.shapiro(data)
print(f'Shapiro-Wilk Test: {delta_cols[i]} \nStatistic: {np.round(stat, 3)} \nP-value: {np.round(p, 3)}')
if p > 0.05:
print(f'Sample {delta_cols[i]} could be normally distributed (fail to reject null hypothesis)')
else:
print(f'Sample {delta_cols[i]} does not look normally distributed (reject null hypothesis)')
print("********************** \n")
stats.probplot(data, dist="norm", plot=axes[i])
axes[i].set_title(f"Normal Q-Q Plot {delta_cols[i]}")
plt.tight_layout()
axes[3].set_position([0.24,0.125,0.228,0.343])
axes[4].set_position([0.55,0.125,0.228,0.343])
axes[5].set_visible(False)
plt.show()Shapiro-Wilk Test: NRS
Statistic: 0.958
P-value: 0.513
Sample NRS could be normally distributed (fail to reject null hypothesis)
**********************
Shapiro-Wilk Test: MPQ
Statistic: 0.957
P-value: 0.55
Sample MPQ could be normally distributed (fail to reject null hypothesis)
**********************
Shapiro-Wilk Test: ODI
Statistic: 0.862
P-value: 0.016
Sample ODI does not look normally distributed (reject null hypothesis)
**********************
Shapiro-Wilk Test: PCS
Statistic: 0.881
P-value: 0.027
Sample PCS does not look normally distributed (reject null hypothesis)
**********************
Shapiro-Wilk Test: BDI
Statistic: 0.96
P-value: 0.607
Sample BDI could be normally distributed (fail to reject null hypothesis)
**********************
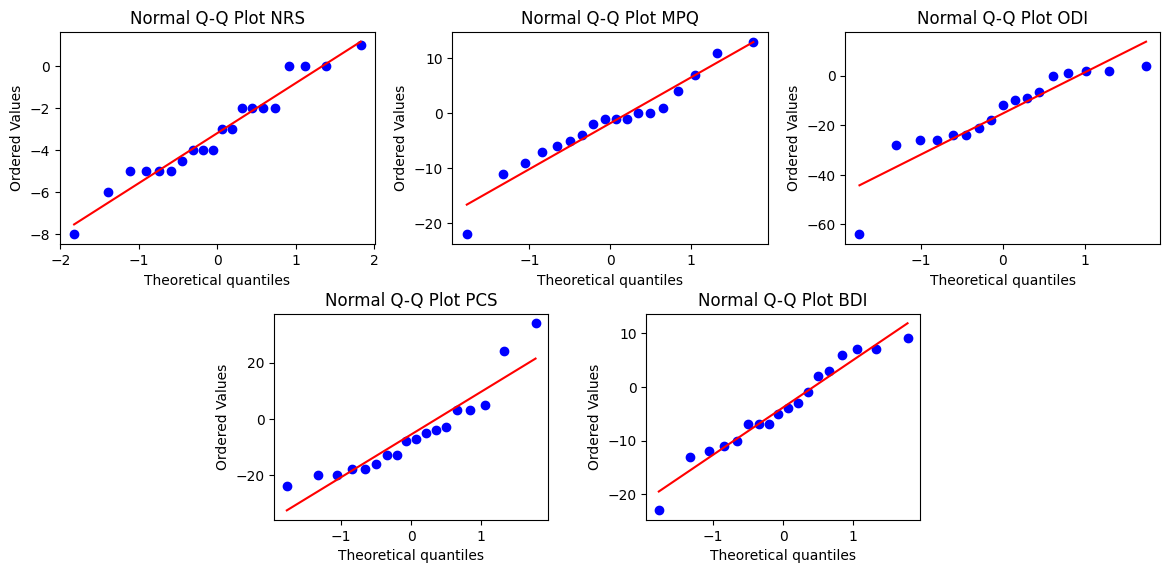
For three of the subjects’ measured treatment effects, Numerical Rating Scale (NRS), McGill Pain Questionnairre (MPQ), and Beck Depression Index (BDI), we fail to reject the null hypothesis and so the differences between effects pre and post operation could be normally distributed. For these three we will test if the underlying distributions of the treatment effects pre and post operation have the same underlying distribution using the Student’s t-test.
For the other two measured treatment effects, Oswestry Disability Index (ODI) and Pain Catastrophizing Scale (PCS), we reject the null hypthesis and assume the difference between treatment effects pre and post operation are not normally distributed. For these two treatment effects we cannot use the Student’s t-test, and will instead use the non-parametric Mann Whitney U Test to test whether the the pre and post operation treatment effect samples hace the same underlying distribution. Because the Mann Whitney U Test is a non-parametric statistical test that does not assume normality, we will also use this test on the other three treatment effects.
Student’s T-Test¶
The Two-Sample, Paired Student’s T-Test is used to test whether two related, sample distributions have a statistically significant difference.
Our null hypothesis is that the averages (or expected) values of the two samples, pre and post treatment effects, are the same.
If the null hypothesis is rejected, then the pre and post operation treatment effect samples do not have identical average (expected) values and the pre and post operation samples could be different, or in other words, the operation may have influenced a change in the measured treatment effect.
If we fail to reject the null hypothesis, then the pre and post operation treatment effect samples could have identical average (expected) values and the operation may not have influenced a change in the measured treatment effect.
delta_cols = ['NRS', 'MPQ', 'BDI']
for col in delta_cols:
df[f'{col} Pre-Op'] = df[f'{col} Pre-Op'].astype('float')
df[f'{col} Post-Op'] = df[f'{col} Post-Op'].astype('float')
resultTtest = stats.ttest_rel(a=df[f'{col} Pre-Op'], b=df[f'{col} Post-Op'], nan_policy='omit')
print(f"Student's t Test: {col} \nStatistic: {np.round(resultTtest.statistic, 3)} \nP-value: {np.round(resultTtest.pvalue, 3)}")
if resultTtest.pvalue > 0.05:
print(f'Pre and Post Op {col} samples could have identical average (expected) values. (fail to reject null hypothesis)')
else:
print(f'Pre and Post Op {col} samples do not have identical average (expected) values. (reject null hypothesis)')
print("********************** \n")Student's t Test: NRS
Statistic: 6.139
P-value: 0.0
Pre and Post Op NRS samples do not have identical average (expected) values. (reject null hypothesis)
**********************
Student's t Test: MPQ
Statistic: 0.961
P-value: 0.35
Pre and Post Op MPQ samples could have identical average (expected) values. (fail to reject null hypothesis)
**********************
Student's t Test: BDI
Statistic: 1.916
P-value: 0.072
Pre and Post Op BDI samples could have identical average (expected) values. (fail to reject null hypothesis)
**********************
We only reject the null hypothesis for the first treatment effect, Numerical Rating Scale (NRS), and fail to reject the null hypothesis for the other two treatment effects McGill Pain Questionnairre (MPQ) and Beck Depression Index (BDI).
Wilcoxon Signed-Rank Test¶
The Wilcoxon Signed-Rank Test is a non-parametric version of the Student’s T-Test used to test if there is a difference between two paired distributions.
It tests the null hypothesis that differences between the paired samples are distributed symetrically around zero. If we reject the null hypothesis, then the paired pre and post operation treatment effects do not have the same underlying distribution, and the operation could have caused a significant difference to the measured treatment effect. And if we fail to reject the null hypothesis, then the paired treatment effect samples could have the same underlying distribution, and the treatment may not have caused a significant difference to the measured treatment effect.
delta_cols = ['NRS', 'MPQ', 'ODI', 'PCS', 'BDI']
for col in delta_cols:
df[f'{col} Pre-Op'] = df[f'{col} Pre-Op'].astype('float')
df[f'{col} Post-Op'] = df[f'{col} Post-Op'].astype('float')
result_wilcoxon_test = stats.wilcoxon(x=df[f'{col} Pre-Op'], y=df[f'{col} Post-Op'], nan_policy='omit', zero_method='wilcox')
print(f"Wilcoxon Signed-Rank Test: {col} \nStatistic: {np.round(result_wilcoxon_test.statistic, 3)} \nP-value: {np.round(result_wilcoxon_test.pvalue, 3)}")
if result_wilcoxon_test.pvalue > 0.05:
print(f'Pre and Post Op {col} samples could have the same underlying distribution. (fail to reject null hypothesis)')
else:
print(f'Pre and Post Op {col} samples do not have the same underlying distribution. (reject null hypothesis)')
print("********************** \n")Wilcoxon Signed-Rank Test: NRS
Statistic: 1.0
P-value: 0.0
Pre and Post Op NRS samples do not have the same underlying distribution. (reject null hypothesis)
**********************
Wilcoxon Signed-Rank Test: MPQ
Statistic: 48.0
P-value: 0.3
Pre and Post Op MPQ samples could have the same underlying distribution. (fail to reject null hypothesis)
**********************
Wilcoxon Signed-Rank Test: ODI
Statistic: 10.0
P-value: 0.003
Pre and Post Op ODI samples do not have the same underlying distribution. (reject null hypothesis)
**********************
Wilcoxon Signed-Rank Test: PCS
Statistic: 44.0
P-value: 0.07
Pre and Post Op PCS samples could have the same underlying distribution. (fail to reject null hypothesis)
**********************
Wilcoxon Signed-Rank Test: BDI
Statistic: 45.5
P-value: 0.081
Pre and Post Op BDI samples could have the same underlying distribution. (fail to reject null hypothesis)
**********************
Like with the Student’s T-Test, we reject the null hypothesis for treatment effect Numerical Rating Scale (NRS), we also reject the null hypothesis for the treatment effect Oswestry Disability Index (ODI). This suggests that there is a statistically significant difference between these measured treatment effects from before and after the subjects’ operations.
For the other three treatment effects, we fail to reject the null hypothesis, and should conclude that there is no significant differences to the measured treatment effects before and after the subjects’ operations.
Conclusions¶
We found large, average percent descreases between pre and post operation data across all five measured treatment effects for subject’s reported pain, depression, and pain induced disability. Using both parametric and non-parametric statistical testing we found there was a statistically significant difference to the subject’s pain and disability as reported with the Numerical Rating Scale for pain and the Oswestry Disability Index for lower-back pain induced disability.
- Quintero, A., Berwal, D., Telkes, I., DiMarzio, M., Harland, T., Morris, D. R., Paniccioli, S., Dalfino, J., Iyassu, Y., McLaughlin, B. L., & Pilitsis, J. G. (2024). Correlating Evoked Electromyography and Anatomic Factors During Spinal Cord Stimulation Implantation With Short-Term Outcomes. Neuromodulation: Technology at the Neural Interface, 27(8), 1470–1478. 10.1016/j.neurom.2024.08.004
- McLaughlin, B. (2024). High-Resolution, Spinal Cord Stimulation for Non-Opioid Treatment of Neuropathic Pain (U44NS115111). Mendeley Data. 10.17632/RMJ2KNGZBP.1